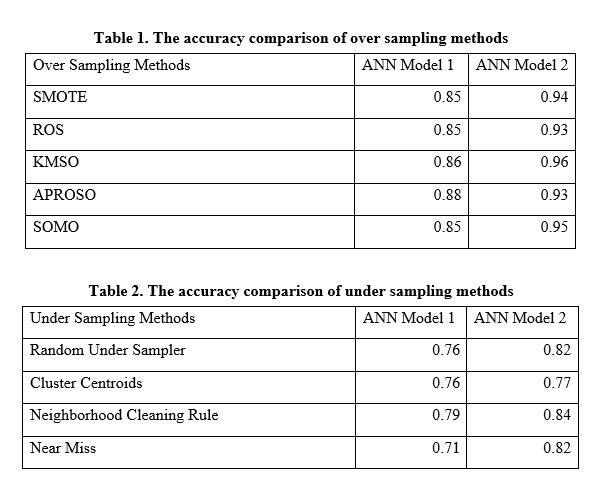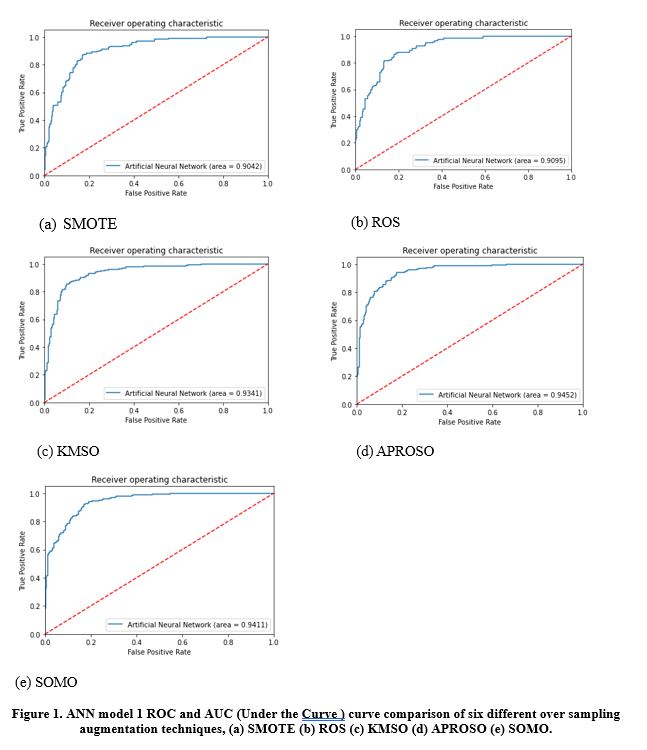
“Many industries prefer using biocolourants, because they are environmentally friendly and safe for human health. For example, food and cosmetics industries are increasingly choosing biocolourants over synthetic alternatives. However, the main challenge has been the lack of information on where to obtain them naturally. In our previous research work, Merlin Sudeepti Savalam utilized deep learning as a machine learning tool to effectively process a large amount of biocolourant data. The present work has focused on examining the plant species from Magnoliopsida and Pinopsida, the two plant classes containing plants with biocolourant properties. The key problem here is the class imbalance in data samples. To resolve this issue, we use five over-sampling methods, i.e., Synthetic Minority Oversampling Technique (SMOTE), Random Over Sampling (ROS), K-Means and Smote-Based Oversampling (KMSO), Affinity Propagation and Random Over Sampling-Based Oversampling (APROSO), and Self-Organizing Map-based Oversampling (SOMO). We also study four under-sampling techniques, i.e., Random Under Sampling (RUS), Cluster Centroids (CCs), Neighborhood Cleaning Rule (NCR), and Near Miss-1 (NM1). In order to evaluate the above over- and under-sampling approaches, we have applied two different deep learning Artificial Neural Network (ANN) models, i.e., ANN model 1 and ANN model 2. The empirical results show that all the over- and under-sampling methods can provide promising results on the ANN model 2, and the over-sampling techniques are more effective in classifying the Magnoliopsida and Pinopsida images. The experimental results obtained are given in the following tables and figure.” – Md. Hasan Sharif –
Md. Hasan Sharif’s M.Sc. thesis was written under the guidance of Profs. Xiao-Zhi Gao and Markku Hauta-Kasari. It is part of the on-going research work, which concentrates on color classification and clustering, specifically in the field of biocolours.